# 过滤器解析器
我们之前说过,模板解析的整体运行流程,先使用HTML解析器解析模板,如果遇到文本就用文本过滤器解析,如果文本中遇到过滤器就使用过滤器解析器解析。
上一小节中,我们介绍了过滤器有两种使用方式,分别是在双花括号插值中和在 v-bind 表达式中。两种使用方式对应的就是两种不同的解析模式。
# v-bind表达式解析
v-bind表达式是属于标签属性,既然是标签属性,那么就是需要在模板编译的HTML解析器进行解析。
我们之前分析过,HTML解析器中负责处理标签的是processAttrs函数,其中跟v-bind有关的如下:
function processAttrs (el) { // 省略无关代码... if (bindRE.test(name)) { // v-bind // 省略无关代码... value = parseFilters(value) // 省略无关代码... } // 省略无关代码... }成功
2
3
4
5
6
7
8
9
可以看到,负责处理过滤器解析器的函数是parseFilters
# 双花括号差值解析
双花括号差值属于文本解析的一部分,文本解析的函数为parseText,其中跟过滤器有关的如下:
export function parseText (text,delimiters){ // 省略无关代码... const exp = parseFilters(match[1].trim()) // 省略无关代码... }成功
2
3
4
5
可以看到,这里负责过滤器解析器的函数也是parseFilters,也就是说,我们只需要分析parseFilters函数的实现就可以
# parseFilters函数
parseFilters函数的定义位于源码的src/complier/parser/filter-parser.js文件中,代码如下:
const validDivisionCharRE = /[\w).+\-_$\]]/ export function parseFilters (exp: string): string { // exp是否在 '' 中 let inSingle = false // exp是否在 "" 中 let inDouble = false // exp是否在 `` 中 let inTemplateString = false // exp是否在 \\ 中 let inRegex = false // 在exp中发现一个 { 则curly加1,发现一个 } 则curly减1,直到curly为0 说明 { ... }闭合 let curly = 0 // 在exp中发现一个 [ 则square加1,发现一个 ] 则square减1,直到square为0 说明 [ ... ]闭合 let square = 0 // 在exp中发现一个 ( 则paren加1,发现一个 ) 则paren减1,直到paren为0 说明 ( ... )闭合 let paren = 0 // 解析游标,每循环过一个字符串游标加1 let lastFilterIndex = 0 let c, prev, i, expression, filters // 从前往后开始一个一个匹配,匹配出那些特殊字符 for (i = 0; i < exp.length; i++) { prev = c c = exp.charCodeAt(i) if (inSingle) { if (c === 0x27 && prev !== 0x5C) inSingle = false } else if (inDouble) { if (c === 0x22 && prev !== 0x5C) inDouble = false } else if (inTemplateString) { if (c === 0x60 && prev !== 0x5C) inTemplateString = false } else if (inRegex) { if (c === 0x2f && prev !== 0x5C) inRegex = false } else if ( c === 0x7C && // 匹配 字符 | exp.charCodeAt(i + 1) !== 0x7C && // 不是 || exp.charCodeAt(i - 1) !== 0x7C && // 不是 || !curly && !square && !paren // 不在() [] {} 之间 ) { if (expression === undefined) { // first filter, end of expression lastFilterIndex = i + 1 // 截取表达式为当前过滤器之前的部分 expression = exp.slice(0, i).trim() } else { // 添加过滤器 pushFilter() } } else { switch (c) { case 0x22: inDouble = true; break // " case 0x27: inSingle = true; break // ' case 0x60: inTemplateString = true; break // ` case 0x28: paren++; break // ( case 0x29: paren--; break // ) case 0x5B: square++; break // [ case 0x5D: square--; break // ] case 0x7B: curly++; break // { case 0x7D: curly--; break // } } if (c === 0x2f) { // / let j = i - 1 let p // find first non-whitespace prev char for (; j >= 0; j--) { p = exp.charAt(j) if (p !== ' ') break } if (!p || !validDivisionCharRE.test(p)) { inRegex = true } } } } // 循环结束,没有定义过过滤器,则去除整个字符串的首位空格 if (expression === undefined) { expression = exp.slice(0, i).trim() // 有过滤器,则保存过滤器最后一部分 } else if (lastFilterIndex !== 0) { pushFilter() } function pushFilter () { // 截取当前过滤器之前的部分,存入filters中 (filters || (filters = [])).push(exp.slice(lastFilterIndex, i).trim()) lastFilterIndex = i + 1 } // 循环完成后,如果过滤器存在,则拼接过滤器render函数 if (filters) { for (i = 0; i < filters.length; i++) { expression = wrapFilter(expression, filters[i]) } } return expression } function wrapFilter (exp: string, filter: string): string { const i = filter.indexOf('(') if (i < 0) { // _f: resolveFilter return `_f("${filter}")(${exp})` // 判断有没有(,代表过滤器中是否有传入参数 } else { const name = filter.slice(0, i) const args = filter.slice(i + 1) return `_f("${name}")(${exp}${args !== ')' ? ',' + args : args}` } }成功
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59
60
61
62
63
64
65
66
67
68
69
70
71
72
73
74
75
76
77
78
79
80
81
82
83
84
85
86
87
88
89
90
91
92
93
94
95
96
97
98
99
100
101
102
103
104
105
106
107
108
109
上述代码看着较为复杂,实际上逻辑比较简单
从头开始遍历传入的exp每一个字符,通过判断每一个字符是否是特殊字符(如',",{,},[,],(,),\,|)进而判断出exp字符串中哪些部分是表达式,哪些部分是过滤器id
如果匹配到',",`字符,说明当前字符在字符串中,那么直到匹配到下一个同样的字符才结束,同时, 匹配 (), {},[] 这些需要两边相等闭合, 那么匹配到的 | 才被认为是过滤器中的|。
当匹配到过滤器中的|符时,那么|符前面的字符串就认为是待处理的表达式,将其存储在 expression 中,后面继续匹配,如果再次匹配到过滤器中的 |符 ,并且此时expression有值,那么说明后面还有第二个过滤器,那么此时两个|符之间的字符串就是第一个过滤器的id,此时调用 pushFilter函数将第一个过滤器添加进filters数组中。
如果遍历完成后,expression仍未被赋值,表示没有发现过滤器,直接将整个字符串去除首尾空格后返回;否则,说明最后一部分字符串也是过滤器的一部分,将其加入filters数组中
最后处理保存在filters数组中的过滤器,调用wrapFilter函数将它们包装起来,并返回最终的表达式。
举个简单的例子,假如有如下过滤器字符串:
message | filter1 | filter2(arg)成功
那么它的匹配过程如下图所示:
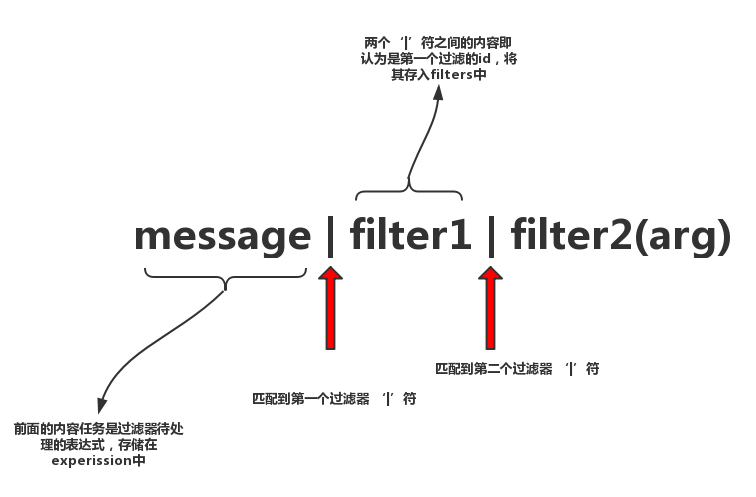
将上例中的过滤器字符串都匹配完毕后,会得到如下结果:
expression = 'message' filters = [ 'filter1', 'filter2(arg)' ]成功
2
接下来遍历得到的filters数组,并将数组的每一个元素及expression传给wrapFilter函数,生成最终的_f函数调用字符串,如下:
_f("filter2")(_f("filter1")(message),arg)成功
这样就最终生成了用户所写的过滤器的_f函数调用字符串。
# 总结
本小节介绍了过滤器是如何从模板字符串编译成最终过滤器_f函数调用字符串的。
首先我们先分析了过滤器两种使用方式,双花括号插值中和在 v-bind 表达式。这两种方式最终都是通过processAttrs函数解析。
然后我们分析了processAttrs函数的具体实现,通过遍历传入的过滤器字符串每一个字符,根据每一个字符是否是一些特殊的字符从而作出不同的处理,最终,从传入的过滤器字符串中解析出待处理的表达式expression和所有的过滤器filters数组。
最后将解析出来的表达式expression和所有的过滤器filters数组,通过wrapFilter拼接成为过滤器_f函数调用字符串